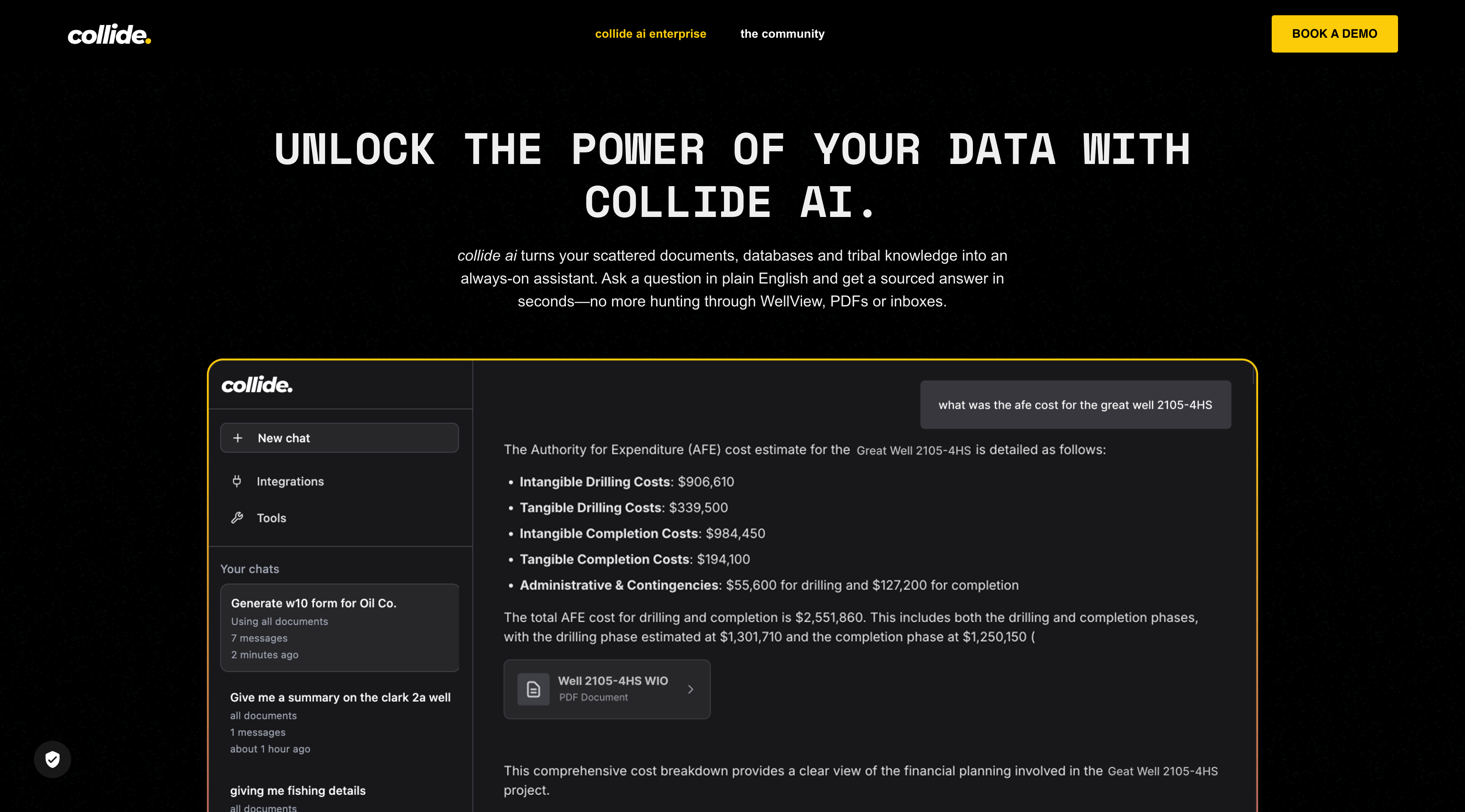
The Challenge
Enterprise energy companies relied on manual search across 100,000+ unstructured documents: PDFs, Word files, Excel spreadsheets, and PowerPoint presentations. Existing tools were slow, inaccurate, and couldn’t handle domain-specific terminology like AFE costs, well logs, and regulatory compliance language.
Searching for a single data point could take analysts hours. Critical decisions were being delayed because the information simply couldn’t be indexed and surfaced fast enough.
The Architecture Solution
I joined the engineering team to lead the complete overhaul and architecture of their RAG-powered LLM system from the ground up, moving them from fragile legacy code to highly scalable, AI-driven infrastructure.
My implementation explicitly tackled the unstructured data ingest bottleneck. I engineered an end-to-end Azure ML pipeline in Python leveraging Document Intelligence, Computer Vision, and Cognitive Search. This completely automated the previously manual ingestion workflows.
To prevent hallucinations, the deterministic retrieval system grounded every LLM answer strictly in original source documents via citation linking, allowing enterprise clients to trace every data point back to its host document. To ensure semantic parsing caught all the deep structural nuance of Oil & Gas data, I fine-tuned transformer models in PyTorch and integrated custom embeddings alongside precise metadata tagging.
Fully Integrated Delivery
The system successfully spanned backend infrastructure through pure frontend visualization:
- Microservice Distributed Ingestion: Leveraged Apache Kafka to handle immense spikes in document uploads without dropping throughput.
- Full-Stack Application Delivery: Developed the complete frontend interfaces for Collide.io using Ruby on Rails, React, and JavaScript. This included implementing the real-time websocket chat interfaces natively into the core Linux hosting environment alongside interactive analytics dashboards.
- Orchestration: Containerized the entire backend and AI stack with Docker and orchestrated the rollout via Kubernetes to maximize uptime.
- Telemetry: Deployed bespoke internal monitoring tracking tools utilizing Python FastAPI and Prometheus to capture ingestion throughput, request latency, and ML pipeline failure rates in real-time.
The Results
By the time I delivered the overhaul, the platform was handling 5 massive enterprise enterprise clients seamlessly.
We achieved 3x faster document retrieval across the entire 100,000+ document datalake. To ensure the legacy fragility never returned, I built comprehensive testing suites utilizing pytest, Jest, and RSpec achieving 90% coverage, deployed through strict Jenkins and GitHub Actions CI/CD pipelines.
The platform’s technical stability and immediate user adoption directly accelerated external investment conversations, contributing significantly to them securing $5M in Seed Funding.